Шпаргалка по проектированию систем
Выбор правильной архитектуры = Выбор правильных сражений + Управление компромиссами
Что оцениваем
\(QPS\) - queries per second (запросы в секунду)
\(RPS\) - reads per second (чтение в секунду)
\(WPS\) - writes per second (запись в секунду)
\(Peak QPS\) = \(QPS * 2\) обычно (пиковый QPS)
\(RW\) - read write ratio (отношение чтения и записи)
\(Message size\) (\(Размер сообщения\))- размер сообщения в байтах, если не указано иное
\(Read Throughput\) (Пропускная способность на чтение) - \(RPS * message size = N\) bytes per second
\(Write Throughput\) (Пропускная способность на запись) - \(WPS * message size = N\) bytes per second
Размышления о максимальной пропускной способности (bandwidth) или ширине полосы
максимальная пропускная способность (bandwidth) — это теоретический предел для соединения. ** Отдельно «пропускная способность» (throughput)** является более практичным показателем. Он отражает фактический объем данных, которые проходят по каналу за определенное время. Продолжая сравнение с дорожным движением, фактическую пропускную способность можно представить, как реальное количество автомобилей, проезжающих через стоп-линию.
Соединение Ethernet 1 gbps/с может выдавать пропускную способность всего лишь 128mb/s, но не более одного гигабита, в секунду.
Storage - обычно хранится в течение N лет.
Storage replica - \(Storage * (2-3 раза)\)
Cache storage - обычно 20% от объема хранилища или около того.
Cache replica storage - \(Cache Storage * (2-3 раза)\)
Базовые цифры
\(10^3\) - 1kb
\(10^6\) - 1mb
\(10^9\) - 1gb
\(10^{12}\) - 1tb
\(10^{15}\) - 1pb
\(10^{18}\) - 1eb
Секунд в сутках = \(24 * 60 * 60 = 86400\), грубо \(10^5\)
ASCI сивол - 1 char - 1 байт
Unicode символ - 1 rune - 4 байта
Mongodb id size - 12 byte. 12-байтовый ObjectId состоит из:
- 4-байтовой временной метки, отражающей создание ObjectId, измеряемой в секундах с момента эпохи Unix.
- 5-байтового случайного значения, генерируемого один раз для каждого процесса. Это случайное значение уникально для машины и процесса.
- 3-байтовый инкрементный счетчик, инициализированный случайным значением
base62 сколько уникальных строк может быть закодировано в base62 hashValue состоит из символов [0-9, a-z, A-Z], число которых равно \(10 + 26 + 26 = 62\). Для этого составим таблицу для \(62^n\)
| n | Уникальные значения |
| 1 | 62^1 = 62 |
| 2 | 62^2 = 3 844 |
| 3 | 62^3 = 238 328 |
| 4 | 62^ 4 = 14 776 336 |
| 5 | 62^5 = 916 132 832 |
| 6 | 62^6 = 56 800 235 584 |
| 7 | 62^7 = 3 521 614 606 208 ~3,5 триллиона |
| 8 | 62^8 = 218 340 105 584 896 |
Степени двойки
| Степень | Точное значение | Примерное значение | Байты |
| 7 | 128 | ||
| 8 | 256 | ||
| 10 | 1024 | 1 тысяча | 1 KB |
| 16 | 65,536 | 64 KB | |
| 20 | 1,048,576 | 1 миллион | 1 MB |
| 30 | 1,073,741,824 | 1 миллиард | 1 GB |
| 32 | 4,294,967,296 | 4 GB | |
| 40 | 1,099,511,627,776 | 1 триллион | 1 TB |
| 50 | 1,125,899,906,842,624 | 1 PB |
Числа задержки, которые должен знать каждый программист
Notes
\[1 ns = 10^{-9} seconds\] \[1 us = 10^{-6} seconds = 1,000 ns\] \[1 ms = 10^{-3} seconds = 1,000 us = 1,000,000 ns\]| Название | ns | us | ms | комментарии |
| Ссылка на L1 cache | 0.5 | |||
| Неправильное предсказание ветви | 5 | |||
| Ссылка на L2 cache | 7 | 14x L1 cache | ||
| Блокировка/разблокировка Mutex | 25 | |||
| Обращение к памяти | 100 | 20x L2 cache, 200x L1 cache | ||
| Сжатие 1 KB в Zippy | 10,000 | 10 | ||
| Отправка 1 KB по сети 1Gbps | 10,000 | 10 | ||
| Случайное чтение с SSD* | 150,000 | 150 | ~1GB/sec SSD | |
| Последовательное чтение 1 MB из памяти | 250,000 | 250 | ||
| Round trip внутри датацентра | 500,000 | 500 | ||
| Последовательное чтение с SSD* | 1,000,000 | 1,000 | 1 | ~1GB/sec SSD, 4X memory |
| Поиск по HDD | 10,000,000 | 10,000 | 10 | 20x datacenter roundtrip |
| Последовательное чтение 1 MB по сети 1 Gbps | 10,000,000 | 10,000 | 10 | 40x memory, 10X SSD |
| Последовательное чтение 1 MB по сети 1 HDD | 30,000,000 | 30,000 | 30 | 120x memory, 30X SSD |
| Отправка пакета CA->Netherlands->CA | 150,000,000 | 150,000 | 150 |
Всякие полезные метрики
- последовательное чтение с HDD на скорости 30 MB/s
- последовательное чтение 1 Gbps Ethernet на скорости 100 MB/s
- последовательное чтение SSD на скорости 1 GB/s
- Последовательное чтение из памяти на скорости 4 GB/s
- 6-7 кругосветных трипов в секунду
- 2,000 трипов в секунду внутри ДЦ
Как оценивать?
- Уточните количество ежедневных пользователей и общее количество пользователей.
- Спросите о количестве запросов от пользователя в среднем. Отсюда вы можете получить QPS.
- Подумайте о пиковых QPS, чтениях и записях.
- Предположите (уточните) размер сообщения.
- Рассчитайте пропускную способность.
- Если это возможно, подумайте о среднем размере данных. Рассчитайте объем хранилища и кэша.
Пример оценки
У вас 10 миллионов ежедневных активных пользователей, каждый из которых делает в среднем 100 запросов на чтение в день, а новые данные создаются 5 раз в день.
RPS = 10M * 100 / 86400 = 12000 r/s
WPS = 10M * 5 / 86400 = 580 w/s
Peak QPS = 24000 r/s
Предположим (уточните у интервьюера), что средний размер читаемого сообщения составляет 50 байт, а записываемого - 1 кб.
Средняя пропускная способность на чтение \(50b * 12*10^3 = 60kb/s\)
Средняя пропускная способность на запись \(1kb * 580 = 580kb/s\)
Здесь мы можем подумать о типе данных/метаданных и т. д. Предположим, что вы уточнили у интервьюера, и размер новых данных составляет 1 kb.
5 лет хранения - 10M * 1kb * 5 раз в день * 365 дней в году * 5 лет = 91tb * 3 = 300tb с репликами.
Предположим, что у вас есть только 10% горячих данных, и вы согласились использовать 20% в качестве кэша.
Хранение кэша - 10% * 90tb * 20% * 3 реплики = 5.5 tb
Основные шаги
Объясните и согласуйте область применения системы
- Кейсы пользователей (описание последовательностей событий, которые, взятые вместе, приводят к тому, что система делает что-то полезное)
- Кто будет ее использовать?
- Как они будут ее использовать?
- Ограничения
- В основном определяют ограничения трафика и обработки данных при масштабировании.
- Масштаб системы, например запросы в секунду, типы запросов, запись данных в секунду, чтение данных в секунду)
- Специальные требования к системе, такие как многопоточность, ориентированность на чтение или запись.
Проектирование архитектуры высокого уровня (абстрактное проектирование).
- Набросайте важные компоненты и связи между ними, но не вдавайтесь в некоторые детали.
- Сервисный уровень приложения (обслуживает запросы)
- Перечислите необходимые сервисы. * Уровень хранения данных * Например, обычно масштабируемая система включает в себя веб-сервер (балансировщик нагрузки), сервис (разделение сервисов), базу данных (кластер баз данных master/slave) и систему кэширования.
Компонентный дизайн
- Компонент + специфические API, необходимые для каждого из них.
- Объектно-ориентированный дизайн для функциональных возможностей.
- Сопоставление функций с модулями: Один сценарий для одного модуля.
- Учитывайте взаимосвязи между модулями:
- Определенные функции должны иметь уникальный экземпляр (Singletons)
- Основной объект может быть составлен из множества других объектов (композиция).
- Один объект является другим объектом (наследование)
- **Дизайн схемы базы данных.
Понимание узких мест
- Возможно, вашей системе нужен балансировщик нагрузки и множество машин, чтобы обрабатывать запросы пользователей.
- Или, возможно, данные настолько велики, что вам необходимо распределить базу данных на нескольких машинах. Какие минусы могут возникнуть при этом?
- Не слишком ли медленно работает база данных и не требуется ли ей кэширование в памяти?
Масштабирование вашей абстрактной конструкции
- Вертикальное масштабирование
- Вы масштабируете, добавляя больше мощности (CPU, RAM) к существующей машине.
- Горизонтальное масштабирование
- Вы масштабируетесь, добавляя больше машин в ваш пул ресурсов.
- Кэширование
- Балансировка нагрузки помогает вам горизонтально масштабировать все большее количество серверов, но кэширование позволит вам гораздо лучше использовать уже имеющиеся ресурсы, а также сделает недостижимыми требования к продуктам.
- Кэширование приложений требует явной интеграции в код самого приложения. Обычно оно проверяет, есть ли значение в кэше; если нет, то извлекает его из базы данных.
- Кэширование базы данных, как правило, “бесплатное”. Когда вы включаете базу данных, вы получаете некоторую конфигурацию по умолчанию, которая обеспечивает определенную степень кэширования и производительности. Эти начальные настройки будут оптимизированы для общего случая использования, и, настроив их в соответствии с шаблонами доступа вашей системы, вы, как правило, сможете добиться значительного повышения производительности.
- Кэш-память наиболее эффективна с точки зрения производительности. Это связано с тем, что они хранят весь набор данных в памяти, а доступ к оперативной памяти на порядки быстрее, чем к диску. например, Memcached или Redis.
- например, предварительный расчет результатов (например, количество посещений с каждого ссылающегося домена за предыдущий день),
- например, предварительная генерация дорогостоящих индексов (например, предлагаемых историй на основе истории кликов пользователя).
- например, хранение копий часто используемых данных в более быстром бэкенде (например, Memcache вместо PostgreSQL).
- Балансировка нагрузки
- Публичные серверы масштабируемого веб-сервиса скрыты за балансировщиком нагрузки. Этот балансировщик равномерно распределяет нагрузку (запросы от ваших пользователей) на группу/кластер серверов приложений.
- Типы: Умный клиент (трудно добиться идеального результата), Аппаратные балансировщики нагрузки ($$$, но надежные), Программные балансировщики нагрузки (гибридные - работают для большинства систем)
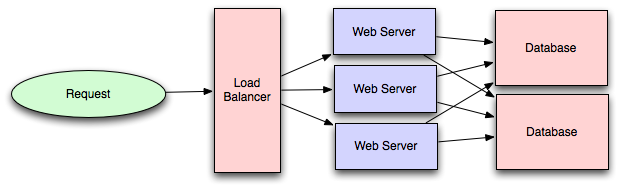
- Репликация базы данных
- Репликация базы данных - это частое электронное копирование данных из базы данных на одном компьютере или сервере в базу данных на другом, чтобы все пользователи имели одинаковый уровень информации. В результате получается распределенная база данных, в которой пользователи могут получить доступ к данным, относящимся к их задачам, не мешая работе других. Реализация репликации базы данных с целью устранения неоднозначности или несогласованности данных между пользователями называется нормализацией.
- Разбиение базы данных
- Разбиение реляционных данных обычно означает декомпозицию таблиц по строкам (горизонтально) или по столбцам (вертикально).
- Map-Reduce
- Для достаточно небольших систем часто можно обойтись специальными запросами к базе данных SQL, но такой подход может не очень хорошо масштабироваться, когда количество хранимых данных или нагрузка на запись потребуют разделения базы данных на шарды, и обычно для выполнения таких запросов требуются выделенные ведомые (в этот момент, возможно, лучше использовать систему, предназначенную для
Спасибо следующим авторам: